java编译执行过程字符编码浅析
本周遇到一个java乱码问题,于是对java的编码问题做了一些实验和了解。简单分析如下:
先看下如下代码:
import java.io.UnsupportedEncodingException;
public class CharSetTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String test = " 篮球 " ;
byte [] defaultResult = test.getBytes();
for ( byte e : defaultResult) {
System. out .print(e + " " );
}
System. out .println(System. getProperty ( "file.encoding" ));
System. out .println( "test=" + test);
}
}1.执行 javac CharSetTest.java,能正常编译,但是得到如下警告:
CharSetTest.java:5: warning: unmappable character for encoding ASCII
String test = "????"; 分析一下为什么会这样呢?对于java编译器来说,CharSetTest.java就是一个文本文件,java编译器要解析这个文本文件并编译生成.class文件。分析了下原因大概是这样的:CharSetTest.java一定是以某一种编码格式来存储的,所以java编译器一定要知道该文本文件时用什么来编码的,如果没有指定就用默认认为文件的编码格式是” ANSI_X3.4-1968”(不同环境可能不一样),所以就会发现无法解释的中文而出现了乱码。 那么以上问题该如何解决,就是要在编译的时候告诉编译器,需要编译的java文件的编码格式,否则编译器有可能遇到不能理解的字符就当做乱码处理了。由于 CharSetTest.java是GBK格式的,所以通过如下命令完成: Javac CharSetTest.java –encoding=GBK。
2. 通过执行Javac CharSetTest.java –encoding=GBK,已经能得到正确的class文件了,但是执行 java CharSetTest,结果如下:
63 63 ANSI_X3.4-1968
test=?? 那么既然已经正确编译了,为什么得到的输出结果还会是乱码呢?前面已经可以肯定.class文件里面存放的中文字符串是正确的了,那原因肯定是在JVM 从.class文件读取这个字符串字节流并构建String对象的时候采用了错误的字符编码来构建字节流。进而导致从JVM输出字符串的字节流到我们控制台的时候,出现乱码。那么很显然,我们必须告诉jvm我们控制台的编码,或者我们希望它采用什么字符编码来构建字节流。如果没有告诉jvm,那么文件的编码格式是” ANSI_X3.4-1968”(不同环境可能不一样)。 假设我们控制台是GBK的编码,那么只要我们正确告诉它,它就能正确的返回字节流了。那么原因就比较简单,我们没有正确告诉JVM我们需要它构造字符串输出流的时候应该采用的编码格式。那么该如何处理呢?通过如下命令: java -Dfile.encoding=GBK CharSetTest 得到结果: -64 -70 -57 -14 GBK test=篮球 以上试验是在linux环境上面做的。在eclipse下面并不会成立,因为eclipse会帮我们做一些判断。同时不同的操作系统环境可能也不一样。
最后总结: Java的class文件采用UTF-8,在JVM里面采用UTF-16。整个过程中编码转换大概可以看下图:
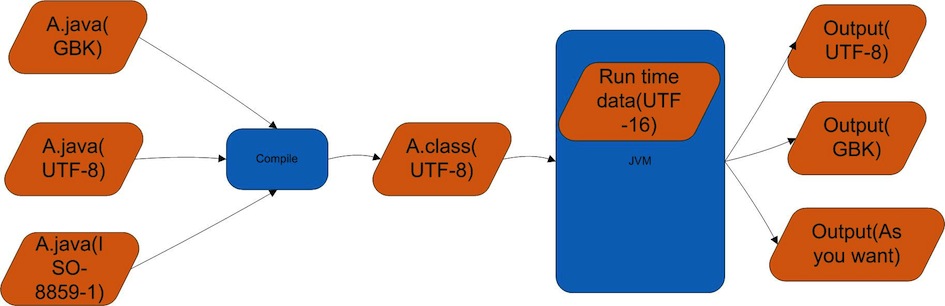
编码转换过程
从上图可以理解不管采用那种格式的源文件,只要正确告诉编译器,编译器就会得到正确的结果。同时只要告诉JVM正确的输出流需要的编码格式,JVM总会返回正确编码格式的输出流。
那么要想不产生乱码要注意两个环节: 1.告诉编译器你的源文件编码。 2.告诉jvm你显示或者构造字符串输出流时希望的编码。 尤其JSP乱码时要注意request请求采用的编码和解析request时候采用的编码是否一致,response的编码和html charset的编码是否一致。
同时我们常遇到jsp、数据库等乱码问题可以找一下是否是以下两种原因: 1.误解型:a文件是GBK编码,但是你以为是UTF-8型编码,所以用UTF-8来理解它,就会出现乱码。 2.无能为力型:a文件时GBK编码,你也知道它是GBK编码,但是你想转换成ISO-8859-1的方式来显示,但是GBK里面有很多字符时ISO- 8859-1所不能解释的,这时也会出现乱码。